Scraping Instagram’s Explore Page can provide invaluable insights into trending content, user behaviors, and emerging influencers. However, scraping social media data is not as straightforward as it might seem. In this article, Hidemyacc will explore how to scrape Instagram Explore, the tools you can use, and how Hidemyacc can streamline the process while staying compliant with Instagram’s guidelines.
1. What is an Instagram Explore page?
The Instagram Explore Page is a personalized feed of content tailored to each user’s interests. It displays a variety of posts that include trending images, videos, and Reels from accounts that the user may not follow. The content here is driven by an Instagram algorithm that analyzes user engagement and behavior to suggest the most relevant posts.
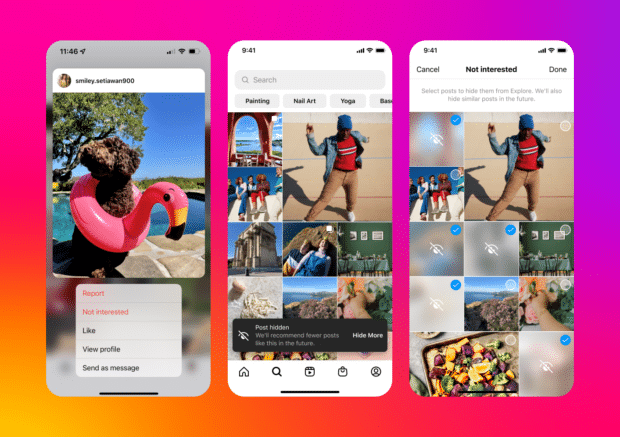
Why do you need to scrape it?
Scraping the Instagram Explore page can be incredibly useful for several reasons such as:
- Trend analysis: By understanding what types of content are trending, marketers and content creators can tailor their strategies to align with the latest trends.
- Competitor research: Businesses can analyze competitors’ content to identify what performs well on Instagram.
- Target audience insights: Scraping Explore content helps you understand the preferences and behaviors of your target audience by observing the types of posts they interact with
Scraping data from Instagram feeds can provide valuable insights into your customers and other important information to support your work.
2. Does Instagram allow users to scrape its data?
Instagram’s terms of service explicitly prohibit unauthorized data scraping. Instagram does not allow automated bots or scripts to collect data from its platform, including the Explore Page, without permission. Violating these terms can result in account suspensions or legal action.
However, Instagram provides Instagram Graph API, which allows developers to access certain public data in a compliant manner. For scraping tasks, always ensure you are operating within Instagram’s legal framework and ethical guidelines.
3. Top 5 best tools to scrape Instagram Explore page
To scrape Instagram Explore Page data, you can use a variety of automated tools. These tools offer different features, ranging from ease of use to high scalability, depending on the volume of data you need. Below are the top 5 tools commonly used for scraping Instagram Explore Page, including how each tool works, and its pros and cons:
1. Selenium
Selenium is an automation tool for web browsers that allows you to programmatically interact with Instagram’s Explore Page. It simulates real user behavior by controlling a web browser, making it ideal for scraping dynamic, JavaScript-heavy content like Instagram.
You can use Selenium to open Instagram, log in, navigate to the Explore Page, and extract data by interacting with HTML elements. It mimics actual browsing actions like scrolling, clicking, and hovering, ensuring you capture content that loads dynamically.
Pros:
- Handles dynamic content: Perfect for scraping pages that load content dynamically via JavaScript (like Instagram).
- Flexibility: You can customize the scraping flow by interacting with the web page in a way that best suits your data needs.
- Realistic behavior: Selenium simulates a human user’s behavior, which reduces the likelihood of getting blocked by Instagram’s anti-bot measures.
Cons:
- Slower than other tools: Because Selenium simulates browser actions, it tends to be slower than other scraping tools.
- Requires coding knowledge: To use Selenium effectively, you need basic programming skills (usually Python or Java), which might not be ideal for beginners.
- Resource-heavy: Running a browser in the background requires more system resources compared to other headless tools.
2. BeautifulSoup with Requests
BeautifulSoup, combined with the Requests library, is a popular choice for scraping static content from Instagram’s Explore Page. Unlike Selenium, which controls a browser, BeautifulSoup is used to parse and extract data from HTML content.

You send HTTP requests to the Instagram website, retrieve the HTML content, and then use BeautifulSoup to extract the data you need. This method works well when Instagram’s Explore Page or the data you want to scrape is already pre-loaded and not heavily reliant on JavaScript.
Pros:
- Faster than Selenium: Since it doesn't require running a browser, scraping with BeautifulSoup is much faster and more resource-efficient.
- Simple and easy to use: BeautifulSoup is simple to use and doesn’t require as much coding experience. It’s beginner-friendly compared to Selenium.
- Lightweight: Does not consume as much memory or CPU compared to a browser-based tool like Selenium.
Cons:
- Limited for dynamic content: BeautifulSoup and Requests are not effective for scraping Instagram’s Explore Page if they rely heavily on JavaScript and dynamic loading.
- Not ideal for large-scale projects: While efficient for small projects, scraping a large number of Instagram posts can be cumbersome and require additional setup for pagination and data extraction.
3. Scrapy
Scrapy is a powerful open-source web scraping framework designed for large-scale web scraping projects. Unlike BeautifulSoup, Scrapy is a full-fledged framework that allows you to build custom spiders to crawl Instagram’s Explore Page and scrape the data.
Scrapy works by creating a “spider” that defines how the data should be scraped and where to save it. It handles requests, follows links, and extracts data from multiple pages simultaneously. Scrapy can handle both static and dynamic content, but it is generally better suited for large datasets.
Pros:
- High performance: Scrapy is faster than both Selenium and BeautifulSoup, especially when scraping large amounts of data.
- Robust for large projects: Its ability to crawl multiple pages and handle complex scraping tasks makes it ideal for large-scale data collection.
- Built-in features: Scrapy comes with built-in support for handling retries, user-agent rotation, and pagination, which makes it highly efficient.
Cons:
- Requires advanced setup: Setting up and using Scrapy requires significant programming knowledge, making it less beginner-friendly.
- Can be overkill for small projects: If you're scraping only a small number of Instagram posts, Scrapy might feel too complicated compared to lighter tools like BeautifulSoup.
- Less flexibility for dynamic pages: While Scrapy can handle JavaScript with the help of additional plugins (like Splash), it is not as flexible as Selenium when dealing with dynamic content.
4. Octoparse
Octoparse is a user-friendly, no-code scraping tool that allows you to scrape Instagram Explore data without any programming knowledge. It provides an intuitive point-and-click interface to select the elements you want to scrape.
Octoparse automatically extracts data based on the rules you define. You can use it to scrape Instagram’s Explore Page by specifying the content you want (e.g., posts, images, captions). The tool handles dynamic content, pagination, and data export for you.
Pros:
- No code required: Octoparse is perfect for non-technical users who want to scrape Instagram Explore data without writing a single line of code.
- Flexible: Handles both static and dynamic content scraping, making it adaptable to various scenarios.
- User-friendly interface: The drag-and-drop functionality makes it easy to set up scraping tasks quickly.
Cons:
- Limitations in the free version: The free version of Octoparse has restrictions on the number of tasks you can run simultaneously, which may limit its utility for larger scraping projects.
- Limited customization: While the tool is user-friendly, it offers less flexibility compared to programming libraries like Selenium and Scrapy, especially when handling very specific scraping requirements.
- Subscription costs: Advanced features are only available in the paid version, which might be costly for frequent or large-scale users.
5. ProxyCrawl
ProxyCrawl is a specialized tool designed to bypass anti-scraping measures like CAPTCHAs and IP blocks. It works by rotating proxies, making requests through different IP addresses, and masking your identity while scraping data.
ProxyCrawl helps you collect data from Instagram’s Explore Page by sending requests from different locations, avoiding detection and blocking. The tool automatically handles proxy rotation, so you don’t need to manage it manually.
Pros:
- Bypass anti-scraping measures: ProxyCrawl helps you avoid getting blocked by Instagram’s anti-scraping measures by rotating IP addresses and managing proxies for you.
- Simple API integration: ProxyCrawl offers an easy-to-use API for integration into your scraping workflows, making it ideal for automation.
- Prevents IP blocks: By using multiple proxies, ProxyCrawl ensures your scraping activities remain undetected by Instagram.
Cons:
- Cost: ProxyCrawl can become expensive, especially for large-scale scraping projects that require frequent requests.
- Limited control: While ProxyCrawl is excellent at avoiding detection, it offers less control over the scraping process itself compared to other tools like Selenium and Scrapy.
- Not a full scraping solution: ProxyCrawl is mainly focused on bypassing detection; you’ll need other tools to handle data extraction and organization.
Each tool has its own set of advantages and disadvantages. Depending on your needs and budget, you can choose the tool that best fits your requirements.
4. How does Hidemyacc help you to scrape Instagram Explore page?
Using an antidetect browser is essential when scraping data. It allows you to create multiple accounts securely, hides your digital fingerprints, and helps you bypass bot protection measures. Additionally, it smoothly integrates with all types of proxies. Here's how Hidemyacc supports you in this process:

- Multiple profile management: Hidemyacc allows users to manage multiple Instagram accounts safely without risking bans. This is especially useful for scraping data from different geographic locations and avoiding suspicion.
- Anti-detection technology: Hidemyacc uses advanced technology to mask your IP, rotate user agents, and mimic real user behavior, reducing the likelihood of detection by Instagram’s anti-scraping algorithms.
- Session management: Hidemyacc offers advanced session management, allowing users to maintain persistent sessions across multiple scraping activities. It also includes anti-detection mechanisms such as browser fingerprint masking and automatic user-agent rotation, ensuring your scraping efforts remain undetected by Instagram’s security systems.
Additionally, Hidemyacc offers an API that allows you to integrate third-party tools, enabling you to run them securely and privately on Hidemyacc profiles.
5. FAQ
Q1: Is scraping Instagram data legal?
Instagram explicitly forbids scraping in its Terms of Service, but using Instagram’s official API for authorized access is compliant with its policies. Always ensure that your scraping activities follow legal and ethical standards.Q2: Can I scrape Instagram Explore Page without using a tool?
Manual scraping (copy-pasting or taking screenshots) is technically possible but inefficient. Automated tools are much faster and scalable, especially for large volumes of data.Q3: What happens if I get caught scraping Instagram?
If you violate Instagram’s terms by scraping data without permission, your account may be suspended or banned, and you could face legal consequences. Always use legal tools and methods for scraping.6. Conclusion
Scraping Instagram’s Explore Page provides valuable insights into trending content and user engagement, but it must be done responsibly and legally. While Instagram’s strict policies make scraping challenging, tools like Selenium, BeautifulSoup, and Hidemyacc provide effective ways to gather Explore Page data while avoiding detection.
Always use the Instagram Graph API when possible, and stay compliant with Instagram’s guidelines to ensure long-term success and avoid penalties.
Further reading:






