Explorar la página de exploración de Instagram puede proporcionar información valiosa sobre el contenido de tendencia, el comportamiento de los usuarios y las personas influyentes emergentes. Sin embargo, extraer datos de las redes sociales no es tan sencillo como podría parecer. En este artículo, Hidemyacc explorará cómo extraer Instagram Explore, las herramientas que puede utilizar y cómo Hidemyacc puede agilizar el proceso sin dejar de cumplir con las pautas de Instagram.
1. ¿Qué es una página de exploración de Instagram?
La página de exploración de Instagram es una fuente personalizada de contenido adaptado a los intereses de cada usuario. Muestra una variedad de publicaciones que incluyen imágenes, videos y carretes de tendencias de cuentas que el usuario quizás no siga. El contenido aquí está impulsado por un algoritmo de Instagram que analiza la participación y el comportamiento del usuario para sugerir las publicaciones más relevantes.
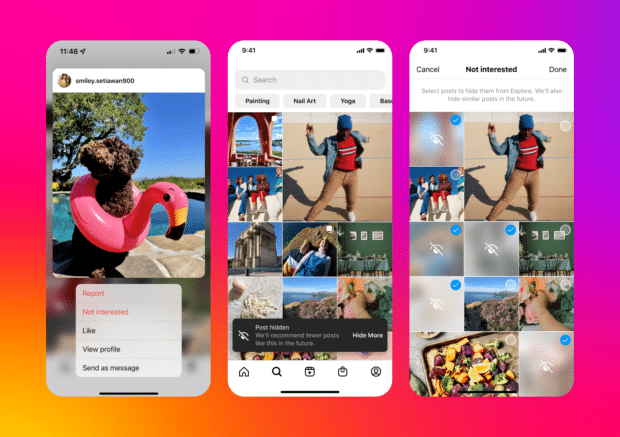
¿Por qué necesitas rasparlo?
Raspar la página Explorar de Instagram puede ser increíblemente útil por varias razones, como por ejemplo:
- Análisis de tendencias: Al comprender qué tipos de contenido están de moda, los especialistas en marketing y los creadores de contenido pueden adaptar sus estrategias para alinearse con las últimas tendencias.
- Investigación de la competencia: Las empresas pueden analizar el contenido de la competencia para identificar qué funciona bien en Instagram.
- Información sobre el público objetivo: El contenido de Scraping Explore lo ayuda a comprender las preferencias y comportamientos de su público objetivo al observar los tipos de publicaciones con las que interactúan.
La extracción de datos de los feeds de Instagram puede proporcionar información valiosa sobre sus clientes y otra información importante para respaldar su trabajo.
2. ¿Instagram permite a los usuarios extraer sus datos?
Los términos de servicio de Instagram prohíben explícitamente la extracción de datos no autorizada. Instagram no permite que bots o scripts automatizados recopilen datos de su plataforma, incluida la página Explorar, sin permiso. La violación de estos términos puede resultar en suspensiones de cuentas o acciones legales.
Sin embargo, Instagram proporciona API de gráficos de Instagram, que permite a los desarrolladores acceder a ciertos datos públicos de manera compatible. Para las tareas de scraping, asegúrese siempre de operar dentro del marco legal y las pautas éticas de Instagram.
3. Las 5 mejores herramientas para extraer la página Explorar de Instagram
Para extraer datos de la página de exploración de Instagram, puede utilizar una variedad de herramientas automatizadas. Estas herramientas ofrecen diferentes características, que van desde facilidad de uso hasta alta escalabilidad, dependiendo del volumen de datos que necesite. A continuación se muestran las 5 herramientas principales que se usan comúnmente para extraer la página de exploración de Instagram, incluido cómo funciona cada herramienta y sus ventajas y desventajas:
1. Selenio
Selenium es una herramienta de automatización para navegadores web que le permite interactuar mediante programación con la página de exploración de Instagram. Simula el comportamiento real del usuario controlando un navegador web, lo que lo hace ideal para extraer contenido dinámico con mucho JavaScript como Instagram.
Puede utilizar Selenium para abrir Instagram, iniciar sesión, navegar a la página de exploración y extraer datos interactuando con elementos HTML. Imita acciones de navegación reales como desplazarse, hacer clic y desplazarse, lo que garantiza que capture contenido que se carga dinámicamente.
Ventajas:
- Maneja contenido dinámico: Perfecto para raspar páginas que cargan contenido dinámicamente a través de JavaScript (como Instagram).
- Flexibilidad: Puede personalizar el flujo de raspado interactuando con la página web de la manera que mejor se adapte a sus necesidades de datos.
- Comportamiento realista: Selenium simula el comportamiento de un usuario humano, lo que reduce la probabilidad de ser bloqueado por las medidas anti-bot de Instagram.
Contras:
- Más lento que otras herramientas: Debido a que Selenium simula las acciones del navegador, tiende a ser más lento que otras herramientas de scraping.
- Requiere conocimientos de codificación: Para utilizar Selenium de forma eficaz, necesita conocimientos básicos de programación (normalmente Python o Java), lo que puede no ser ideal para principiantes.
- Con muchos recursos: Ejecutar un navegador en segundo plano requiere más recursos del sistema en comparación con otras herramientas sin cabeza.
2. BeautifulSoup con solicitudes
BeautifulSoup, combinado con la biblioteca de Solicitudes, es una opción popular para extraer contenido estático de la página de exploración de Instagram. A diferencia de Selenium, que controla un navegador, BeautifulSoup se utiliza para analizar y extraer datos del contenido HTML.

Envía solicitudes HTTP al sitio web de Instagram, recupera el contenido HTML y luego usa BeautifulSoup para extraer los datos que necesita. Este método funciona bien cuando la página de exploración de Instagram o los datos que desea extraer ya están precargados y no dependen en gran medida de JavaScript.
Ventajas:
- Más rápido que el selenio: Dado que no requiere ejecutar un navegador, el scraping con BeautifulSoup es mucho más rápido y utiliza más recursos.
- Sencillo y fácil de usar: BeautifulSoup es fácil de usar y no requiere tanta experiencia en codificación. Es apto para principiantes en comparación con Selenium.
- Ligero: No consume tanta memoria ni CPU en comparación con una herramienta basada en navegador como Selenium.
Contras:
- Limitado para contenido dinámico: BeautifulSoup y Requests no son efectivos para eliminar la página de exploración de Instagram si dependen en gran medida de JavaScript y la carga dinámica.
- No es ideal para proyectos a gran escala: Si bien es eficaz para proyectos pequeños, eliminar una gran cantidad de publicaciones de Instagram puede resultar engorroso y requerir una configuración adicional para la paginación y la extracción de datos.
3. Desguazado
Scrapy es un potente marco de web scraping de código abierto diseñado para proyectos de web scraping a gran escala. A diferencia de BeautifulSoup, Scrapy es un marco completo que le permite crear arañas personalizadas para rastrear la página de exploración de Instagram y extraer los datos.
Scrapy funciona creando una "araña" que define cómo se deben extraer los datos y dónde guardarlos. Maneja solicitudes, sigue enlaces y extrae datos de varias páginas simultáneamente. Scrapy puede manejar contenido tanto estático como dinámico, pero generalmente es más adecuado para grandes conjuntos de datos.
Ventajas:
- Rendimiento alto: Scrapy es más rápido que Selenium y BeautifulSoup, especialmente cuando se extraen grandes cantidades de datos.
- Robusto para grandes proyectos: Su capacidad para rastrear varias páginas y manejar tareas complejas de raspado lo hace ideal para la recopilación de datos a gran escala.
- Funciones integradas: Scrapy viene con soporte incorporado para manejar reintentos, rotación de agentes de usuario y paginación, lo que lo hace altamente eficiente.
Contras:
- Requiere configuración avanzada: Configurar y usar Scrapy requiere importantes conocimientos de programación, lo que lo hace menos amigable para los principiantes.
- Puede ser excesivo para proyectos pequeños: Si solo estás recopilando una pequeña cantidad de publicaciones de Instagram, Scrapy puede parecer demasiado complicado en comparación con herramientas más livianas como BeautifulSoup.
- Menos flexibilidad para páginas dinámicas: Si bien Scrapy puede manejar JavaScript con la ayuda de complementos adicionales (como Splash), no es tan flexible como Selenium cuando se trata de contenido dinámico.
4. Octoparse
Octoparse es una herramienta de extracción sin código fácil de usar que le permite extraer datos de Instagram Explore sin ningún conocimiento de programación. Proporciona una interfaz intuitiva de apuntar y hacer clic para seleccionar los elementos que desea extraer.
Octoparse extrae datos automáticamente según las reglas que usted define. Puede usarlo para extraer la página de exploración de Instagram especificando el contenido que desea (por ejemplo, publicaciones, imágenes, subtítulos). La herramienta maneja contenido dinámico, paginación y exportación de datos por usted.
Ventajas:
- No se requiere código: Octoparse es perfecto para usuarios no técnicos que desean extraer datos de Instagram Explore sin escribir una sola línea de código.
- Flexible: Maneja la extracción de contenido tanto estático como dinámico, lo que lo hace adaptable a diversos escenarios.
- Interfaz fácil de usar: La funcionalidad de arrastrar y soltar facilita la configuración rápida de tareas de scraping.
Contras:
- Limitaciones en la versión gratuita: La versión gratuita de Octoparse tiene restricciones en la cantidad de tareas que puede ejecutar simultáneamente, lo que puede limitar su utilidad para proyectos de scraping más grandes.
- Personalización limitada: Si bien la herramienta es fácil de usar, ofrece menos flexibilidad en comparación con bibliotecas de programación como Selenium y Scrapy, especialmente cuando se manejan requisitos de scraping muy específicos.
- Costos de suscripción: Las funciones avanzadas solo están disponibles en la versión paga, lo que puede resultar costoso para usuarios frecuentes o de gran escala.
5. Rastreo de proxy
ProxyCrawl es una herramienta especializada diseñada para evitar medidas anti-scraping como CAPTCHA y bloques de IP. Funciona rotando servidores proxy, realizando solicitudes a través de diferentes direcciones IP y enmascarando su identidad mientras recopila datos.
ProxyCrawl te ayuda a recopilar datos de la página de exploración de Instagram enviando solicitudes desde diferentes ubicaciones, evitando la detección y el bloqueo. La herramienta maneja automáticamente la rotación de proxy, por lo que no es necesario administrarla manualmente.
Ventajas:
- Evite las medidas anti-raspado: ProxyCrawl te ayuda a evitar que te bloqueen las medidas anti-scraping de Instagram al rotar direcciones IP y administrar servidores proxy por ti.
- Integración API sencilla: ProxyCrawl ofrece una API fácil de usar para la integración en sus flujos de trabajo de scraping, lo que la hace ideal para la automatización.
- Previene bloqueos de IP: Al utilizar varios servidores proxy, ProxyCrawl garantiza que Instagram no detecte sus actividades de scraping.
Contras:
- Costo: ProxyCrawl puede resultar costoso, especialmente para proyectos de scraping a gran escala que requieren solicitudes frecuentes.
- Control limitado: Si bien ProxyCrawl es excelente para evitar la detección, ofrece menos control sobre el proceso de raspado en comparación con otras herramientas como Selenium y Scrapy.
- No es una solución de raspado completa: ProxyCrawl se centra principalmente en eludir la detección; Necesitará otras herramientas para manejar la extracción y organización de datos.
Cada herramienta tiene su propio conjunto de ventajas y desventajas. Dependiendo de tus necesidades y presupuesto podrás elegir la herramienta que mejor se ajuste a tus necesidades.
>>> Más sobre Instagram:
- Cómo colaborar para publicar en Instagram : 10 consejos de expertos para alcanzar el alcance
- Cómo comprar seguidores de Instagram : Consejos seguros y sitios confiables
- Automatización de Instagram Secretos: elija la herramienta adecuada hoy
- Cómo correr con seguridad Varias cuentas de Instagram Sin ser baneado
4. ¿Cómo te ayuda Hidemyacc a eliminar la página de exploración de Instagram?
El uso de un navegador antidetección es esencial al extraer datos. Le permite crear varias cuentas de forma segura, oculta sus huellas digitales y le ayuda a evitar las medidas de protección de bots. Además, se integra perfectamente con todo tipo de servidores proxy. Así es como Hidemyacc te apoya en este proceso:

- Gestión de múltiples perfiles: Hidemyacc permite a los usuarios administrar múltiples cuentas de Instagram de forma segura sin correr el riesgo de prohibiciones. Esto es especialmente útil para extraer datos de diferentes ubicaciones geográficas y evitar sospechas.
- Tecnología antidetección: Hidemyacc utiliza tecnología avanzada para enmascarar su IP, rotar agentes de usuario e imitar el comportamiento real del usuario, lo que reduce la probabilidad de detección por parte de los algoritmos anti-scraping de Instagram.
- Gestión de sesiones: Hidemyacc ofrece gestión avanzada de sesiones, lo que permite a los usuarios mantener sesiones persistentes en múltiples actividades de scraping. También incluye mecanismos antidetección, como el enmascaramiento de huellas dactilares del navegador y la rotación automática de agente de usuario, lo que garantiza que sus esfuerzos de raspado no sean detectados por los sistemas de seguridad de Instagram.
Además, Hidemyacc ofrece una API que le permite integrar herramientas de terceros, permitiéndole ejecutarlas de forma segura y privada en los perfiles de Hidemyacc.
5. Preguntas frecuentes
P1: ¿Es legal extraer datos de Instagram?
Instagram prohíbe explícitamente el scraping en sus Términos de servicio, pero el uso de la API oficial de Instagram para acceso autorizado cumple con sus políticas. Asegúrese siempre de que sus actividades de scraping sigan los estándares legales y éticos.P2: ¿Puedo extraer la página de exploración de Instagram sin utilizar una herramienta?
El scraping manual (copiar y pegar o tomar capturas de pantalla) es técnicamente posible pero ineficiente. Las herramientas automatizadas son mucho más rápidas y escalables, especialmente para grandes volúmenes de datos.P3: ¿Qué pasa si me pillan haciendo scraping en Instagram?
Si viola los términos de Instagram al extraer datos sin permiso, su cuenta puede ser suspendida o prohibida y usted podría enfrentar consecuencias legales. Utilice siempre herramientas y métodos legales para el scraping.6. Conclusión
La extracción de la página de exploración de Instagram proporciona información valiosa sobre el contenido de tendencia y la participación de los usuarios, pero debe hacerse de manera responsable y legal. Si bien las estrictas políticas de Instagram dificultan el scraping, herramientas como Selenium, BeautifulSoup y Hidemyacc brindan formas efectivas de recopilar datos de la página de exploración y evitar la detección.
Utilice siempre la API Graph de Instagram cuando sea posible y cumpla con las pautas de Instagram para garantizar el éxito a largo plazo y evitar sanciones.






