Scrape dữ liệu từ trang Khám phá của Instagram có thể mang lại những insight cực kỳ giá trị về xu hướng nội dung, hành vi người dùng và những influencer đang nổi. Tuy nhiên, việc thu thập dữ liệu từ mạng xã hội không đơn giản như nhiều người nghĩ. Trong bài viết này, Hidemyacc sẽ hướng dẫn bạn cách scrape trang Khám phá Instagram, giới thiệu các công cụ bạn có thể sử dụng, và cách Hidemyacc giúp bạn tối ưu quy trình này mà vẫn đảm bảo tuân thủ các chính sách của Instagram.
1. Trang Khám phá Instagram là gì?
Trang Khám phá (Explore) trên Instagram là một nguồn cấp nội dung được cá nhân hoá theo sở thích riêng của từng người dùng. Nó hiển thị nhiều dạng bài đăng khác nhau — từ ảnh, video đến Reels — đến từ các tài khoản mà bạn có thể chưa từng theo dõi. Những nội dung này được chọn lọc bởi thuật toán của Instagram, dựa trên cách bạn tương tác và hành vi sử dụng để đề xuất những bài viết phù hợp nhất.
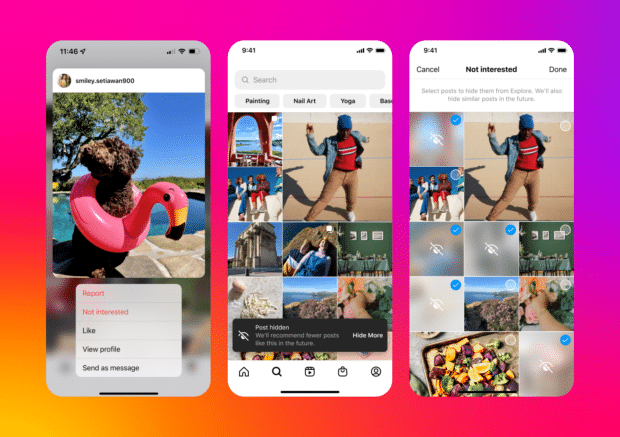
Tại sao cần scrape dữ liệu từ trang Khám phá?
Việc scrape trang Khám phá Instagram có thể cực kỳ hữu ích trong nhiều trường hợp, chẳng hạn như:
- Phân tích xu hướng: Khi nắm được loại nội dung nào đang thịnh hành, các marketer và người làm nội dung có thể điều chỉnh chiến lược để bám sát các xu hướng mới nhất.
- Nghiên cứu đối thủ: Doanh nghiệp có thể phân tích nội dung từ các đối thủ để biết dạng bài nào hoạt động tốt trên Instagram.
- Hiểu rõ hành vi người dùng: Scrape nội dung từ trang Khám phá giúp bạn nắm bắt sở thích và hành vi của nhóm khách hàng mục tiêu, thông qua các loại bài viết mà họ tương tác.
Việc thu thập dữ liệu từ nguồn cấp nội dung Instagram không chỉ giúp bạn hiểu khách hàng rõ hơn mà còn mang lại nhiều thông tin giá trị để hỗ trợ công việc kinh doanh.
2. Instagram có cho phép người dùng scrape dữ liệu không?
Theo điều khoản dịch vụ của Instagram, việc scrape dữ liệu không được cấp phép là bị cấm hoàn toàn. Instagram không cho phép các bot hay script tự động thu thập dữ liệu từ nền tảng của họ, bao gồm cả trang Khám phá. Nếu vi phạm, bạn có thể bị treo tài khoản hoặc đối mặt với các vấn đề pháp lý.
Tuy nhiên, Instagram có cung cấp Instagram Graph API, cho phép developer truy cập một phần dữ liệu công khai một cách hợp pháp. Vì vậy, khi thực hiện các tác vụ liên quan đến scrape, bạn cần đảm bảo tuân thủ quy định và giới hạn pháp lý mà Instagram đưa ra.
3. Top 5 công cụ tốt nhất để scrape trang Khám phá Instagram
Để thu thập dữ liệu từ trang Khám phá Instagram, bạn có thể sử dụng nhiều công cụ tự động khác nhau. Mỗi công cụ lại có những ưu điểm riêng – từ dễ sử dụng đến khả năng mở rộng cao, tuỳ vào lượng dữ liệu bạn cần thu thập. Dưới đây là 5 công cụ phổ biến nhất được dùng để scrape trang Khám phá, kèm theo cách hoạt động, điểm mạnh và điểm yếu của từng cái:
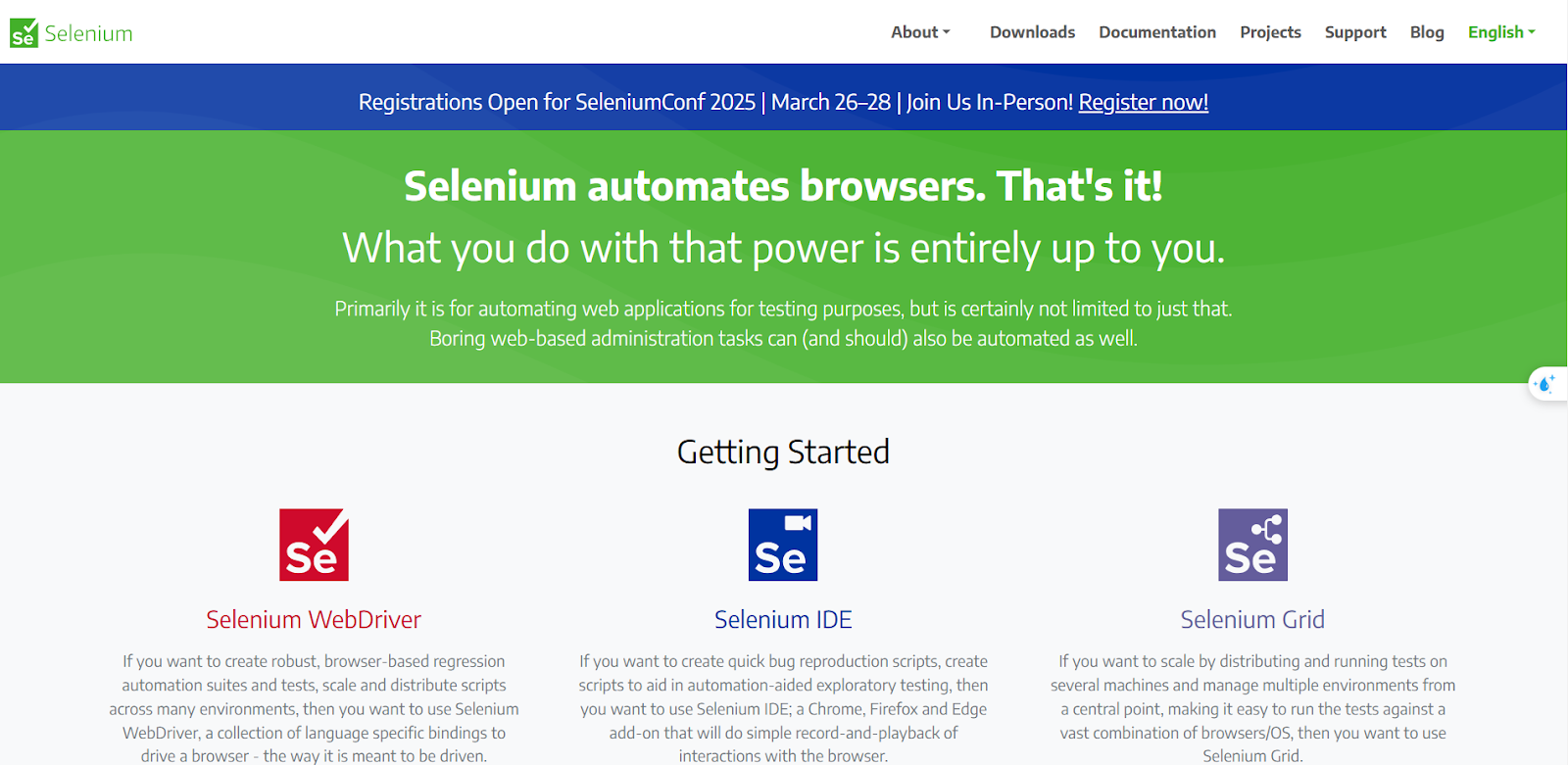
1. Selenium
Selenium là một công cụ tự động hóa trình duyệt web, cho phép bạn tương tác với trang Khám phá của Instagram bằng cách lập trình. Nó mô phỏng hành vi người dùng thực sự bằng cách điều khiển trình duyệt, rất phù hợp để scrape những nội dung động và phụ thuộc nhiều vào JavaScript như Instagram.
Bạn có thể dùng Selenium để mở Instagram, đăng nhập, điều hướng đến trang Khám phá và trích xuất dữ liệu thông qua việc tương tác với các phần tử HTML. Nó tái hiện các thao tác duyệt web như cuộn trang, nhấp chuột và di chuột, giúp bạn thu thập đầy đủ những nội dung được tải động.
Ưu điểm:
- Xử lý nội dung động tốt: Rất phù hợp để scrape các trang sử dụng JavaScript để tải nội dung (như Instagram).
- Linh hoạt: Bạn có thể tuỳ chỉnh toàn bộ quy trình scrape theo cách tương tác với trang sao cho phù hợp nhất với nhu cầu dữ liệu.
- Hành vi giống người thật: Selenium mô phỏng hành vi người dùng thật, giúp giảm nguy cơ bị Instagram phát hiện và chặn bot.
Nhược điểm:
- Chạy chậm hơn các công cụ khác: Do Selenium mô phỏng hành động trình duyệt thật nên tốc độ thu thập dữ liệu thường chậm hơn.
- Cần biết lập trình: Để dùng Selenium hiệu quả, bạn cần có kiến thức lập trình cơ bản (thường là Python hoặc Java), không thật sự phù hợp với người mới bắt đầu.
- Tốn tài nguyên: Việc chạy trình duyệt ngầm khiến công cụ tiêu tốn nhiều tài nguyên hệ thống hơn so với các công cụ dạng headless khác.
2. BeautifulSoup kết hợp với Requests
BeautifulSoup, khi được sử dụng cùng thư viện Requests, là một lựa chọn phổ biến để scrape các nội dung tĩnh từ trang Khám phá của Instagram. Khác với Selenium điều khiển trình duyệt thật, BeautifulSoup được dùng để phân tích cú pháp và trích xuất dữ liệu từ nội dung HTML.

Bạn sẽ gửi các HTTP request đến trang web Instagram, lấy nội dung HTML trả về và sau đó dùng BeautifulSoup để trích xuất các dữ liệu cần thiết. Phương pháp này hoạt động hiệu quả khi nội dung của trang Khám phá hoặc dữ liệu bạn cần đã được tải sẵn và không phụ thuộc quá nhiều vào JavaScript.
Ưu điểm:
- Nhanh hơn Selenium: Vì không cần chạy trình duyệt nên việc scrape bằng BeautifulSoup diễn ra nhanh hơn và tiết kiệm tài nguyên hơn nhiều.
- Đơn giản, dễ sử dụng: BeautifulSoup khá dễ học và không đòi hỏi nhiều kinh nghiệm lập trình, thân thiện hơn với người mới so với Selenium.
- Nhẹ: Ít tiêu tốn bộ nhớ và CPU hơn các công cụ dựa trên trình duyệt như Selenium.
Nhược điểm:
- Hạn chế với nội dung động: BeautifulSoup kết hợp với Requests không hiệu quả trong việc scrape các trang hoặc dữ liệu phụ thuộc nhiều vào JavaScript và tải động – như trang Khám phá của Instagram.
- Không lý tưởng cho dự án lớn: Dù hoạt động tốt với các dự án nhỏ, việc scrape một lượng lớn bài đăng trên Instagram có thể trở nên phức tạp, cần thêm bước xử lý như phân trang và trích xuất nâng cao.
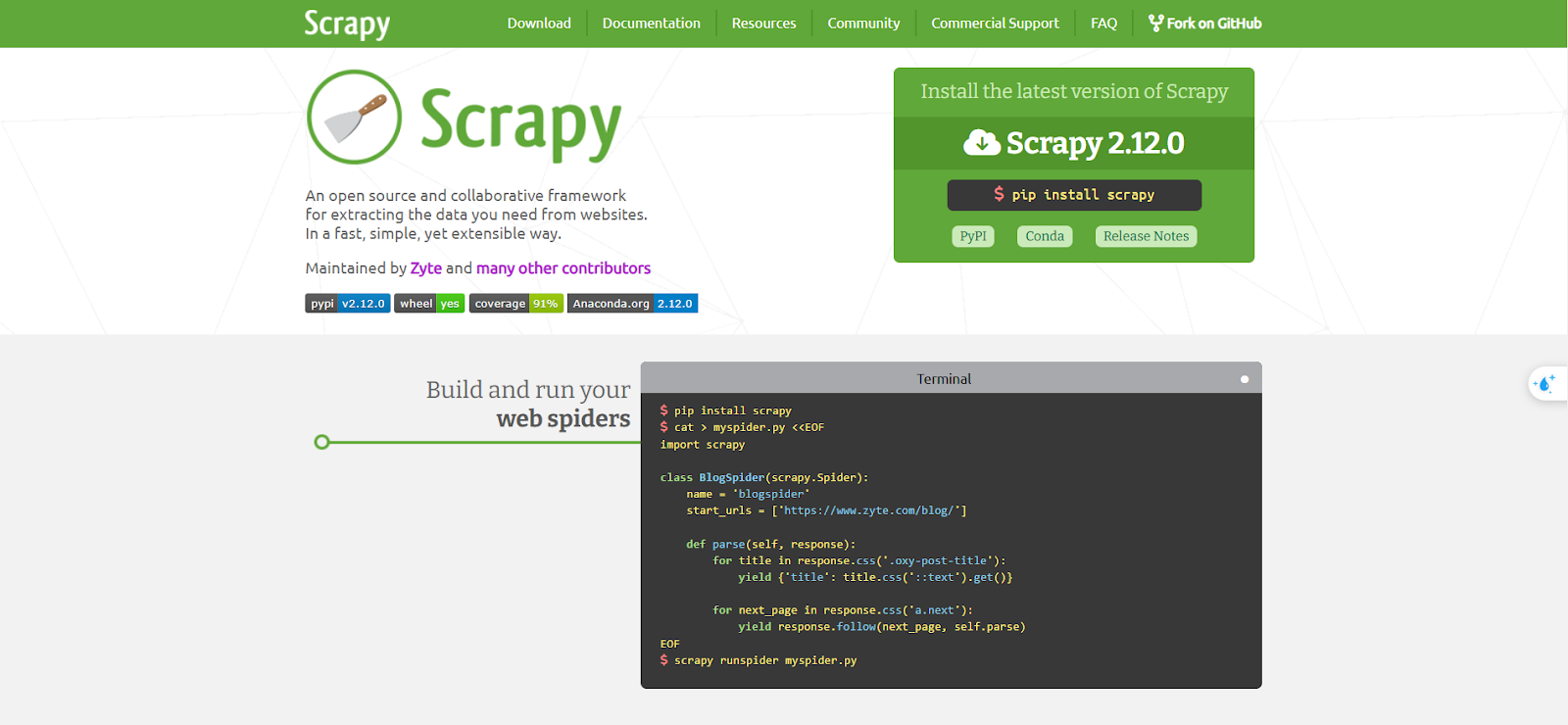
3. Scrapy
Scrapy là một framework mã nguồn mở mạnh mẽ, được thiết kế dành riêng cho các dự án web scraping quy mô lớn. Khác với BeautifulSoup chỉ là một thư viện phân tích HTML, Scrapy là một framework đầy đủ chức năng, cho phép bạn xây dựng các "spider" tùy chỉnh để thu thập dữ liệu từ trang Khám phá của Instagram.
Scrapy hoạt động bằng cách tạo ra một "spider" – định nghĩa cách thu thập dữ liệu và nơi lưu trữ kết quả. Nó xử lý các request, tự động theo liên kết và trích xuất dữ liệu từ nhiều trang cùng lúc. Scrapy có thể xử lý cả nội dung tĩnh lẫn động, nhưng thường được đánh giá là phù hợp hơn cho các bộ dữ liệu lớn.
Ưu điểm:
- Hiệu suất cao: Scrapy nhanh hơn cả Selenium và BeautifulSoup, đặc biệt khi cần scrape lượng dữ liệu lớn.
- Phù hợp với dự án lớn: Có khả năng crawl nhiều trang và xử lý các tác vụ phức tạp, rất lý tưởng cho việc thu thập dữ liệu quy mô lớn.
- Tích hợp nhiều tính năng: Scrapy đi kèm sẵn các tính năng như retry khi gặp lỗi, xoay vòng user-agent, xử lý phân trang… giúp quá trình scrape hiệu quả hơn.
Nhược điểm:
- Cần thiết lập phức tạp: Việc cài đặt và sử dụng Scrapy đòi hỏi kiến thức lập trình nâng cao, không phù hợp lắm với người mới.
- Quá “nặng” cho dự án nhỏ: Nếu bạn chỉ cần scrape một số lượng bài đăng nhỏ, Scrapy có thể sẽ hơi phức tạp và dư thừa so với các công cụ nhẹ như BeautifulSoup.
- Hạn chế với trang động: Dù Scrapy có thể xử lý JavaScript thông qua plugin như Splash, nhưng vẫn không linh hoạt bằng Selenium khi làm việc với nội dung động.
4. Octoparse
Octoparse là công cụ scrape dữ liệu thân thiện với người dùng, không cần viết mã, cho phép bạn thu thập dữ liệu từ trang Khám phá Instagram mà không cần kiến thức lập trình. Giao diện dạng “chọn và nhấp” (point-and-click) giúp bạn dễ dàng chọn các phần tử muốn scrape.
Octoparse sẽ tự động trích xuất dữ liệu dựa trên các quy tắc bạn thiết lập. Bạn có thể dùng nó để scrape nội dung từ trang Khám phá Instagram như: bài viết, hình ảnh, caption,… Công cụ này hỗ trợ xử lý nội dung động, phân trang và xuất dữ liệu hoàn toàn tự động.

Ưu điểm:
- Không cần biết code: Octoparse cực kỳ phù hợp với người không có nền tảng kỹ thuật nhưng vẫn muốn scrape dữ liệu từ trang Khám phá Instagram mà không cần viết một dòng code nào.
- Linh hoạt: Hỗ trợ thu thập dữ liệu cả nội dung tĩnh và động, giúp thích ứng với nhiều tình huống khác nhau.
- Giao diện thân thiện: Chức năng kéo–thả (drag-and-drop) giúp thiết lập các tác vụ scrape nhanh chóng và dễ dàng.
Nhược điểm:
- Giới hạn trong bản miễn phí: Phiên bản free bị hạn chế số lượng tác vụ có thể chạy cùng lúc, gây bất tiện nếu bạn cần thu thập dữ liệu quy mô lớn.
- Tùy chỉnh hạn chế: Dù dễ dùng, Octoparse không linh hoạt như các thư viện lập trình như Selenium hay Scrapy, đặc biệt là khi bạn cần thu thập dữ liệu theo cách rất cụ thể.
- Chi phí đăng ký: Các tính năng nâng cao chỉ có trong bản trả phí, có thể gây tốn kém nếu bạn dùng thường xuyên hoặc làm dự án lớn.
5. ProxyCrawl
ProxyCrawl là một công cụ chuyên biệt giúp vượt qua các biện pháp chống scrape như CAPTCHA và chặn IP. Nó hoạt động bằng cách xoay vòng proxy, gửi request qua nhiều địa chỉ IP khác nhau, từ đó che giấu danh tính trong quá trình thu thập dữ liệu.
ProxyCrawl giúp bạn thu thập dữ liệu từ trang Khám phá Instagram bằng cách gửi request từ nhiều địa điểm khác nhau, giảm thiểu khả năng bị phát hiện hoặc chặn. Công cụ này tự động xử lý việc xoay IP nên bạn không cần quản lý thủ công.
Ưu điểm:
- Vượt qua hệ thống chống scrape: ProxyCrawl giúp bạn tránh bị Instagram phát hiện hoặc chặn bằng cách tự động xoay IP và quản lý proxy.
- API dễ tích hợp: ProxyCrawl cung cấp API thân thiện, dễ tích hợp vào quy trình scrape tự động của bạn.
- Ngăn chặn bị chặn IP: Việc dùng nhiều proxy giúp các hoạt động scrape của bạn ẩn danh và khó bị Instagram phát hiện.
Nhược điểm:
- Chi phí: ProxyCrawl có thể khá tốn kém, đặc biệt nếu bạn scrape với tần suất cao hoặc quy mô lớn.
- Ít quyền kiểm soát: Dù rất tốt trong việc tránh bị chặn, ProxyCrawl không cung cấp nhiều quyền kiểm soát quy trình scrape như các công cụ như Selenium hay Scrapy.
- Không phải giải pháp toàn diện: ProxyCrawl tập trung vào việc vượt qua kiểm soát, bạn vẫn cần các công cụ khác để xử lý và tổ chức dữ liệu thu thập được.
Mỗi công cụ đều có điểm mạnh và điểm yếu riêng. Tuỳ vào nhu cầu và ngân sách, bạn có thể chọn công cụ phù hợp nhất với mình.
>>> Thông tin thêm về Instagram:
- Cách cộng tác đăng bài trên Instagram : 10 lời khuyên của chuyên gia để tiếp cận
- Cách mua người theo dõi trên Instagram : Lời khuyên an toàn và các trang web đáng tin cậy
- Tự động hóa Instagram bí mật: Hãy chọn đúng công cụ ngay hôm nay
- Cách chạy an toàn Nhiều tài khoản Instagram Không bị cấm
4. Hidemyacc hỗ trợ bạn scrape trang Khám phá Instagram như thế nào?
Việc sử dụng một antidetect browser là yếu tố then chốt khi thực hiện các tác vụ scrape dữ liệu. Công cụ này giúp bạn tạo và quản lý nhiều tài khoản một cách an toàn, ẩn đi các dấu vết số (digital fingerprints), đồng thời vượt qua các cơ chế bảo vệ chống bot. Ngoài ra, nó cũng tương thích mượt mà với mọi loại proxy. Dưới đây là cách Hidemyacc hỗ trợ bạn trong quá trình này:

- Quản lý nhiều profile dễ dàng: Hidemyacc cho phép bạn quản lý nhiều tài khoản Instagram một cách an toàn, giảm thiểu nguy cơ bị khóa. Điều này đặc biệt hữu ích khi bạn cần scrape dữ liệu từ nhiều khu vực địa lý khác nhau mà không gây nghi ngờ cho hệ thống của Instagram.
- Công nghệ chống phát hiện: Hidemyacc sử dụng công nghệ tiên tiến để che giấu IP, xoay vòng user-agent và mô phỏng hành vi người dùng thật, giúp bạn tránh bị các thuật toán chống scrape của Instagram phát hiện.
- Quản lý session thông minh: Hidemyacc hỗ trợ quản lý phiên đăng nhập nâng cao, cho phép bạn duy trì trạng thái đăng nhập ổn định trong suốt quá trình scrape. Kết hợp với các cơ chế như ẩn fingerprint trình duyệt và tự động xoay user-agent, Hidemyacc giúp mọi hoạt động scrape của bạn luôn "vô hình" với hệ thống bảo mật của Instagram.
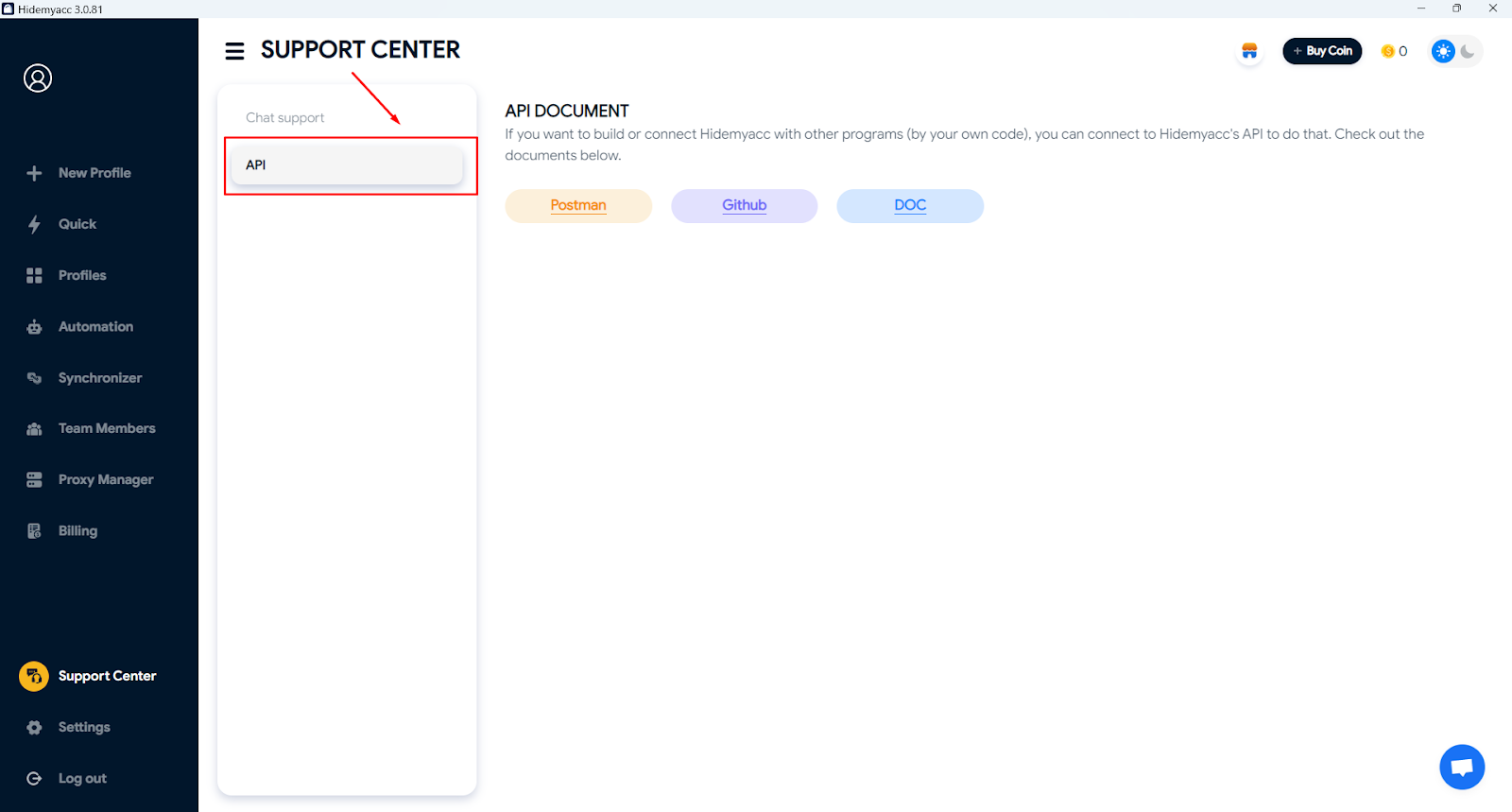
Đồng thời, Hidemyacc cung cấp API cho phép bạn tích hợp các công cụ bên thứ ba, giúp chạy các công cụ scrape một cách an toàn và riêng tư ngay trên các profile của Hidemyacc.
5. Câu hỏi thường gặp
Q1: Scrape dữ liệu từ Instagram có hợp pháp không?
Instagram nghiêm cấm hành vi scrape dữ liệu trong Điều khoản dịch vụ của mình. Tuy nhiên, việc sử dụng API chính thức của Instagram để truy cập dữ liệu công khai là hoàn toàn hợp lệ và tuân thủ chính sách. Hãy luôn đảm bảo rằng mọi hoạt động scrape của bạn đều đúng pháp luật và đạo đức.Q2: Có thể scrape trang Khám phá Instagram mà không cần dùng công cụ không?
Bạn hoàn toàn có thể scrape thủ công (copy thủ công hoặc chụp màn hình), nhưng cách này rất tốn thời gian và không hiệu quả. Các công cụ tự động sẽ nhanh hơn nhiều và có thể xử lý lượng dữ liệu lớn dễ dàng hơn.Q3: Nếu bị phát hiện đang scrape Instagram thì sao?
Nếu bạn vi phạm điều khoản của Instagram bằng cách scrape dữ liệu mà không được phép, tài khoản có thể bị treo hoặc khoá vĩnh viễn. Trong một số trường hợp, bạn còn có thể đối mặt với hậu quả pháp lý. Vì vậy, hãy luôn sử dụng các công cụ và phương pháp hợp pháp.6. Kết luận
Việc scrape dữ liệu từ trang Khám phá Instagram mang lại nhiều insight giá trị về nội dung thịnh hành và mức độ tương tác người dùng – nhưng cần được thực hiện một cách có trách nhiệm và hợp pháp. Mặc dù chính sách nghiêm ngặt của Instagram khiến việc scrape gặp nhiều khó khăn, các công cụ như Selenium, BeautifulSoup, và Hidemyacc vẫn giúp bạn thu thập dữ liệu hiệu quả mà không bị phát hiện.
Luôn ưu tiên sử dụng Instagram Graph API khi có thể và tuân thủ đúng hướng dẫn của Instagram để đảm bảo hoạt động scrape ổn định lâu dài, tránh bị xử phạt hay khóa tài khoả.






